
发布日期:2025-10-26 09:07 点击次数:160
最近 AI 圈又出新花活儿了,DeepSeek 团队悄咪咪地开源了一个 30 亿参数的小模子,名叫 DeepSeek-OCR。
别看体量不大,想法但是够炸的:他们竟然规划让 AI 用看图的神志去读文本。
没错,真“看图识字”。
况且不仅仅识字,而是让“视觉模态”成为一种文本压缩介质,用图片来代表笔墨,用“视觉 token ”取代“文本 token ”,达成所谓的光学压缩(Optical Compression)。
说真话,老狐看到这论文内容的时候,第一响应是:他们是想让言语模子也上好意思术课?
不外仔细一想,还真挺有兴趣兴趣。
大言语模子(LLM)最大的痛点是什么?处理长文本太烧算力。
全球齐知说念,大模子的负责力机制复杂度是宽泛级的。你给它 2 倍的输入,它要算 4 倍的东西;你让它记取一通盘长文档,它坐窝运行“烧卡烧心”。
那能不可换个念念路?DeepSeek 团队说:既然一张图能装下很多字,那不如把文本凯旋形成图像,再让模子去看图!
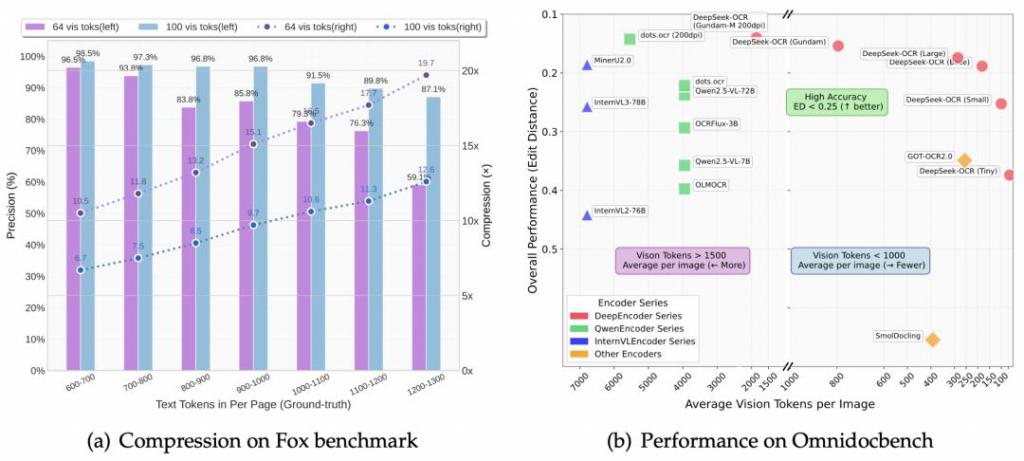
论文里有个罕见直不雅的例子:正本 1000 个 token 智商抒发的内容,刻下只用 100 个视觉 token 科罚,压缩 10 倍,还能保留 97% 的 OCR 准确率。
再狠点,压缩 20 倍也还能保留约 60% 的准确率。这意味着,模子“读图”的效力,竟然比“读字”还高。
换句话说,模子没丢太多信息,但算力工作轻了十倍。

不少网友看到这里齐傻了:AI 处理图像用量比长文本还少?这反东说念主类直观啊!
也有网友嗟叹:DeepSeek 这是想让模子“看文档像刷一又友圈”相同自尊。
老狐认为,这波操作不错称得上“反向降维打击”。
昔时咱们齐在想目标让模子更懂笔墨、看得更远;DeepSeek 凯旋反着来:让模子把字形成画,再“看画识文”。有点像回到了东说念主类最原始的换取神志:象形。
说到这儿,得聊聊这模子到底咋作念的。DeepSeek-OCR 由两部分构成:DeepEncoder(看图压缩)+DeepSeek3B-MoE(解码规复)。
前者是通盘系统的“压缩引擎”,它把两大视觉猛将 SAM-base 和 CLIP-large 串起来:
SAM 负责盯细节的“窗口负责力”,CLIP 负责持合座的“全局负责力”。中间还塞了个 16 × 卷积压缩模块,有利砍 token。
比如说,一张 1024 × 1024 的图片,表面上要被切成 4096 块去向理,刻下被这个压缩模块一刀下去,凯旋瘦身成几百个 token。
这么一来,既保留了昭着度,又不炸显存。
况且它还维持多档鉴别率步地:Tiny、Small、Base、Large,还有一个代号叫 “ Gundam(高达)” 的动态步地。
你没看错,这模子甚而取名齐带点“中二魂”。
解码器部分则是 DeepSeek 的资本行:MoE(羼杂内行)架构。
64 个内行中每次只激活 6 个,再加两个分享内行,本色算力只动用了约 5.7 亿参数,但性能比好意思 30 亿模子。又快又省,号称“节能灯中的斗争机”。
它的任务也不复杂,等于从那些压缩后的视觉 token 里,把笔墨“解码”追思。
通盘经过有点像 OCR 的升级版,不外,此次是模子我方在“看图猜字”,而不是东说念主类教它识字,况且猜得相配准。
固然,要把这玩意训好,得先喂够粮。DeepSeek 这回但是下了血本:整整 3000 万页 PDF 文档,涵盖 100 种言语,其中中英文就占 2500 万页。
他们还整了个“模子飞轮”:先用一个版面分析模子粗标数据,再用 GOT-OCR 之类的模子作念精标,窥察一遍,再反过来标更多半据。
月盈则食,模子我方喂我方长大。

除此以外,还有 300 万条 Word 文档,有利练公式识别、HTML 表格提真金不怕火,甚而包括金融图表、化学结构式、几何图形等奇奇怪怪的图像结构,也齐被塞进窥察聚会。
DeepSeek 还从 LAION、Wukong 这些开源数据集持了中英文各 1000 万张场景图,用 PaddleOCR 标注。
不错说,这波窥察,真的是“从理工科到艺术科全消灭”,真确切正用数据砸出来的灵巧脑袋。
那成果咋样?论文里放了几组铁心,相配能打。
在 OmniDocBench 测试上,DeepSeek-OCR 用 100 个视觉 token 就跨越了 GOT-OCR2.0(每页 256 token)。用不到 800 个视觉 token,又突出了 MinerU2.0(每页 6000+ token)。
性能更强、输入更短、推理更快。
这速率,几乎是“ AI 印刷机”。
不外,最让老狐拍桌嗟叹的,是论文终末阿谁脑洞:光学压缩还能模拟东说念主类渐忘?
东说念主脑的挂牵会随时刻零落,往事暗昧,新事昭着。DeepSeek 团队就讨论:那 AI 能不可也学会“忘”?
如果 AI 也能像东说念主相同“领受性挂牵”,是不是就能在超长对话里活得更自尊?
他们设计了一个施行想象:跨越第 k 轮的历史对话内容,就渲染成图像;先压一遍,减少 10 倍 token;再久远少许,接续减轻图像尺寸;图像越小,信息越暗昧,最终就“忘掉”了。
有网友看完凯旋嗟叹:这不等于在模拟东说念主脑挂牵机制嘛!
固然,也有东说念主泼凉水:DeepSeek 的幻觉高得惊东说念主,这如果再给它学会“忘”,怕是忘得比东说念主还快。
老狐看完这部分,是真认为有点形而上学意味。AI 的挂牵,到底该无尽延展,如故学会渐忘?
DeepSeek 给出的谜底是后者,它用视觉的神志,让模子在“压缩”的同期,也“过滤”掉冗余。就像东说念主脑那样:只留有效的信息。
这背后的道理,比 OCR 自己更大。它在从头界说“高下文”的主意:不是谨记多,而是谨记精。
说到底,DeepSeek-OCR 看似是个 OCR 模子,实则是在试探一种新范式:能不可用视觉模态来高效承载言语信息?
在总共东说念主齐往“更大、更长、更贵”的标的卷的时候,DeepSeek 却反手作念了个“更小、更快、更巧”的模子。
这事儿自己就很 DeepSeek。
老狐终末想说一句:AI 的进化,可能并不老是加法,无意候减法更优雅。
DeepSeek-OCR 等于个活生生的例子:一个 3B 小模子,玩出了长文本压缩的新念念路,甚而顺遂摸到了“挂牵与渐忘”的规模。
如果说前年是“谁能记取更多”凯发·k8国际app娱乐,那本年,可能是“谁能忘得更灵巧”。而 DeepSeek,此次又走在了前头。
